Back in 2022-2023, I encountered an interesting bug that caused unreclaimable kernel memory growth on Ubuntu servers running containerized workloads. The key word here is unreclaimable — this memory cannot be freed without rebooting the kernel. No echo 3 > /proc/sys/vm/drop_caches, no service restart, no container reboot. Only a full host node reboot releases it.
The Configuration
A systemd unit that restarts on failure:
[Unit]
After=network-online.target
Wants=network-online.target
StartLimitIntervalSec=0
[Service]
Type=exec
DynamicUser=true
ExecStart=bash -c 'echo bug; exit 1'
ProtectSystem=strict
ProtectHome=yes
ProtectKernelModules=yes
ProtectKernelLogs=yes
ProtectControlGroups=yes
ProtectClock=yes
PrivateDevices=yes
PrivateTmp=yes
RestartSec=1ms
Restart=always
[Install]
WantedBy=multi-user.target
The daemon would exit if a required network interface or config file wasn’t present, then restart. During network issues or misconfigurations, this created restart loops — accumulating over days and weeks.
Observed Behavior
SUnreclaimin/proc/meminfogrowing slowly but steadily- Eventually OOM kills across unrelated processes
- Container restarts did nothing — the memory is in host kernel space
- Only host node reboot reclaimed the memory
This last point is critical for containerized environments (LXC/LXD/Proxmox). The kernel is shared between all containers. When unreclaimable slab grows, you cannot fix it by restarting the affected container. You must reboot the entire host — taking down all workloads on that node.
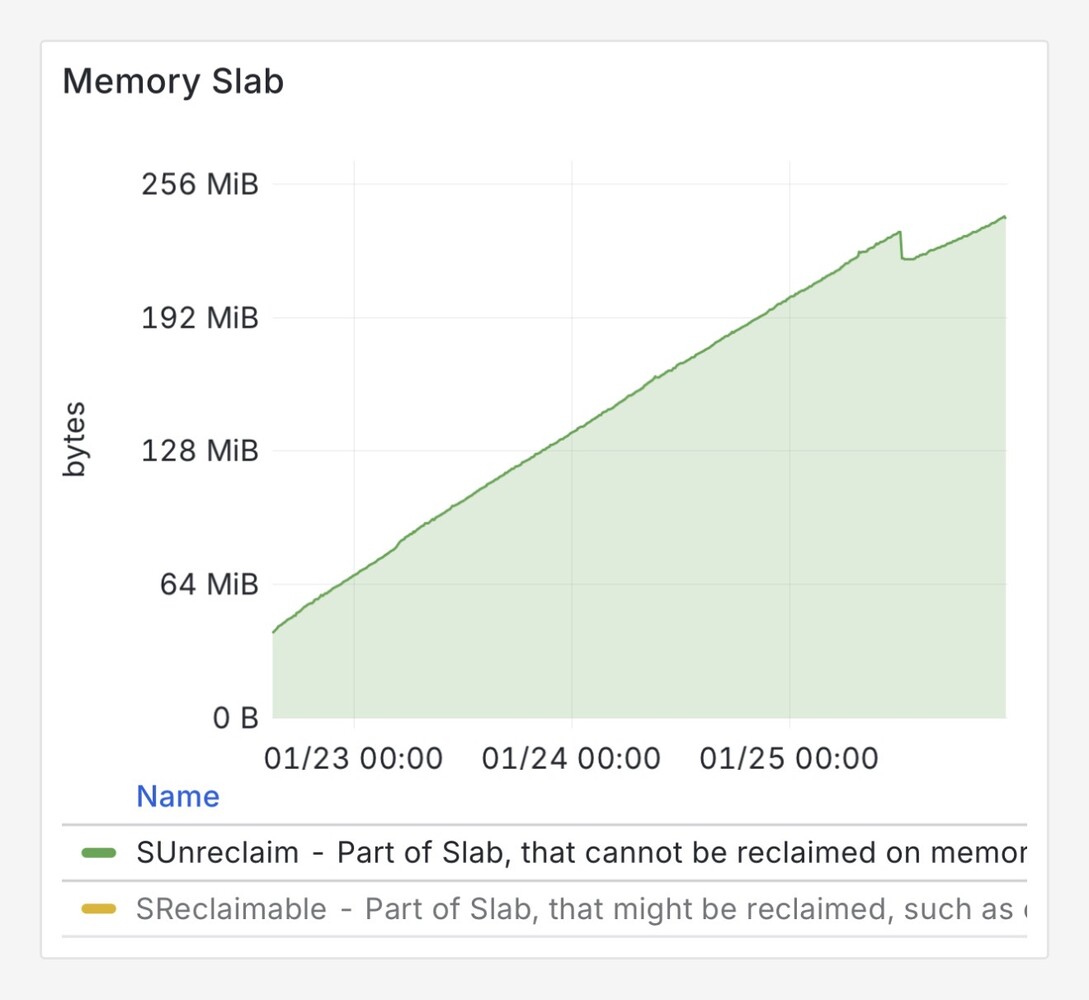
SUnreclaim stable growing ~60mb/day — seems to slow, but multiplies fast on multi-container envs
Root Cause: Cgroup Memory Accounting Bug
The Linux kernel has a bug in cgroup memory controller. When systemd creates and destroys cgroups:
mem_cgroup_css_alloc()allocates kernel structures for each new cgroupmem_cgroup_css_offline()is called when cgroup is removed- But
mem_cgroup_css_free()is NOT always called
The percpu_ref reference counting mechanism fails to fully release the structures. These allocations go into slab_unreclaimable — kernel memory that cannot be reclaimed by any means except reboot.
ByteDance engineers documented this with kprobe analysis: alloc/offline counts matched, but alloc/free counts diverged over time. Each restart cycle leaked a small amount. Over days of normal operation with occasional restart loops, this accumulated into gigabytes.
I confirmed the bug by temporarily setting RestartSec=1ms — the rapid restarts made SUnreclaim grow visibly in real-time, which proved the correlation.
Why Type=exec Amplifies the Problem
Type=simple:
- Direct fork of the target process
- Single cgroup creation per service start
Type=exec:
- Spawns systemd-executor first
- Executor configures namespaces, sandboxing, cgroup hierarchy
- Then exec’s the target binary
- Multiple cgroup operations per restart cycle
Switching from Type=exec to Type=simple reduced cgroup churn significantly, which slowed the leak enough to be manageable.
The Fix
Just set Type=simple is mostly enough. Also set RestartSec around ~10-15s.
And, obviously, fix your service not to fail so often 😉
Alternative Mitigations
- Upgrade to Ubuntu 24.04+ with latest kernel updates
- Boot parameter
cgroup.memory=nokmemdisables kernel memory accounting - Disable memory accounting for specific units:
MemoryAccounting=no
Affected Versions
I observed this bug on:
- Ubuntu 18.04 (kernel 4.15, cgroups v1)
- Ubuntu 20.04 (kernel 5.4, cgroups v2)
The bug affects both cgroups v1 and v2. Full fixes arrived with later kernel updates in 22.04 (5.15+) or through backported patches.
Monitoring
# Unreclaimable slab — this number should be stable over time
watch -n 60 'grep SUnreclaim /proc/meminfo'
# If SUnreclaim keeps growing, check which slab caches are responsible
slabtop -o | head -20
# Memory cgroup count (growing = potential leak)
cat /proc/cgroups | grep memory
# Find services with frequent restarts
journalctl --since "24 hours ago" | grep -E "Started.*\.service" | sort | uniq -c | sort -rn | head -10
Related Bug Reports and Articles
Kernel/Systemd Issues:
- https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=912411 — ByteDance’s original report with kprobe analysis
- https://github.com/systemd/systemd/issues/8015 — systemd-logind memory leak on SSH connections
- https://github.com/systemd/systemd/issues/14639 — cred_jar slab growth with socket activation
- https://bugs.launchpad.net/bugs/1750013 — systemd-logind session leak on Ubuntu
Kubernetes/Container Ecosystem:
- https://github.com/kubernetes/kubernetes/issues/61937 — cgroup leak with kernel memory accounting enabled
- https://github.com/kubernetes-sigs/kind/issues/421 — memory cgroup leaks in kind clusters
- https://github.com/canonical/lxd/issues/5405 — unreclaimable slab growth in LXD
- https://github.com/deckhouse/deckhouse/issues/2152 — kmalloc-4k leak with systemd cgroupDriver
Technical Analysis:
- https://www.sobyte.net/post/2022-01/memory-cgroup/ — NetEase kernel team’s deep dive with kernel-level fix
Summary
The combination of:
- Kernel bug in cgroup memory accounting
Type=execoverhead (multiple cgroup operations per start)- Services that restart frequently over time
- Containerized environment (shared kernel)
Creates a scenario where unreclaimable kernel memory grows until OOM. The debugging path is non-obvious — the leak is in kernel space, and container restarts provide no relief. You only discover it when the host goes down.
If you’re running Ubuntu 18.04/20.04 LTS with services that restart frequently — monitor your SUnreclaim and consider switching to Type=simple.